Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Abstract
Social and collaborative platforms emit multivariate time-series traces in which early interactions - such as views, likes, or downloads - are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets—arXiv (accesses → citations of 2.3M papers) and GitHub (pushes → stars/forks of 3M repositories)—and outline additional domains with analogous lead–lag dynamics, including Wikipedia (page-views → edits), Spotify (streams → concert attendance), e-commerce (click-throughs → purchases), and LinkedIn profile (views → messages). Our datasets provide ideal testbeds for lead–lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data.
ArXiv Dataset
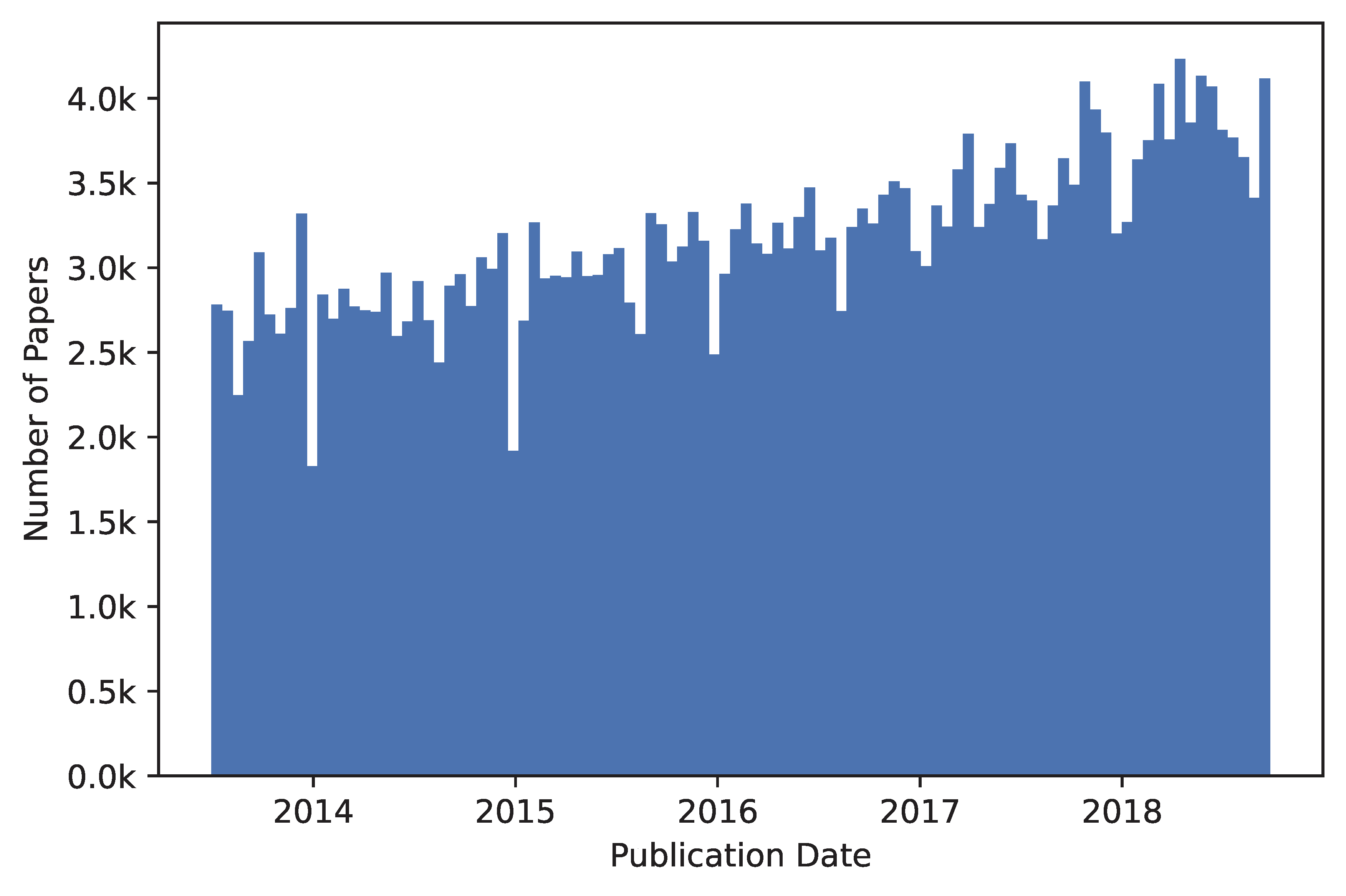
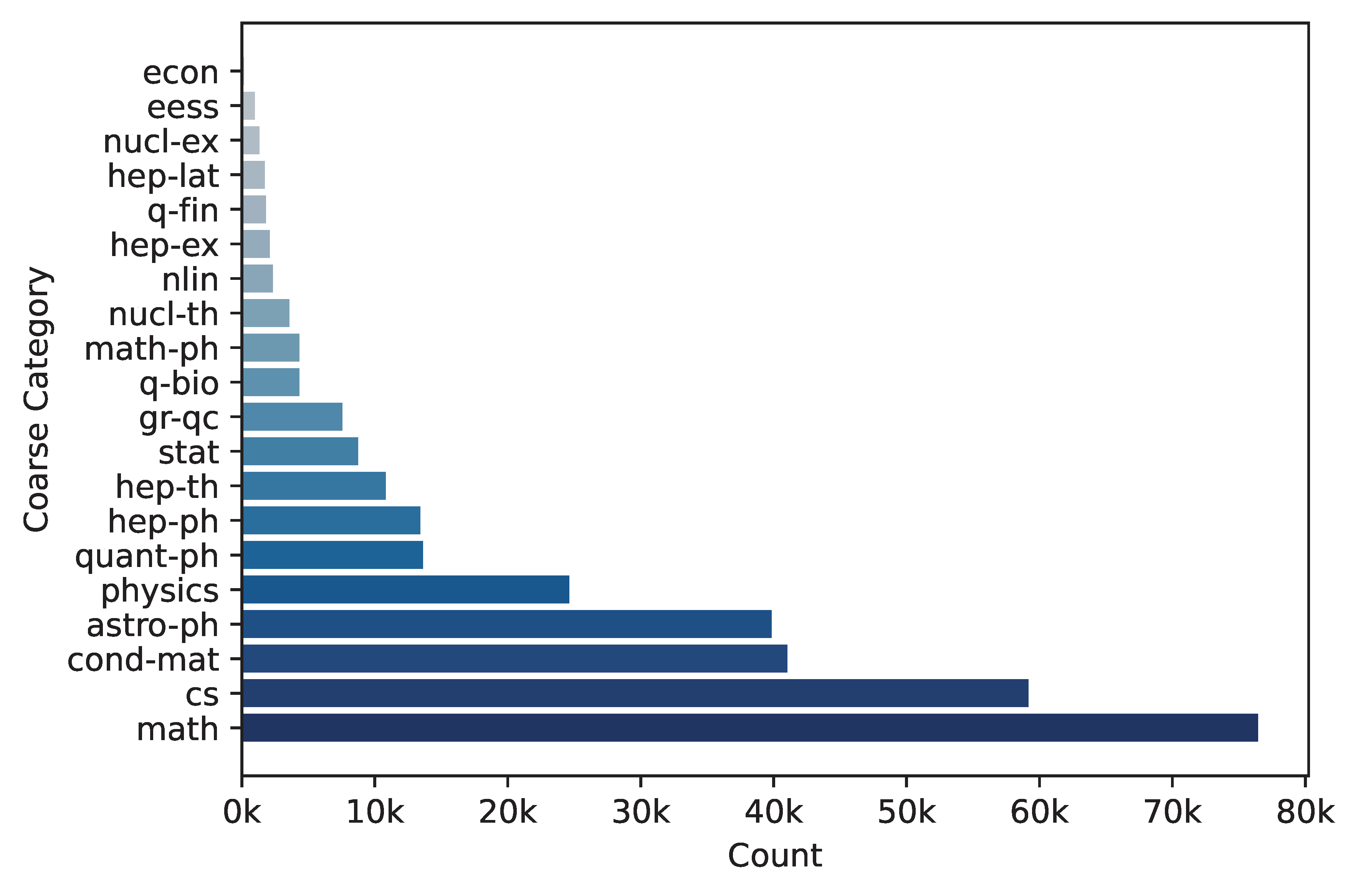
Our ArXiv dataset couples access logs with citation trajectories to study lead–lag dynamics between early usage and long-term scholarly impact. We construct access time series from ArXiv web logs (weekly coverage from 2006-07-03 to 2013-06-30; daily from 2013-07-01 onward), remove likely bots (≈44% of 4.87B raw downloads), and aggregate per paper. We then join these records with the Semantic Scholar dump (≈220M papers; ≈2.66B citation pairs), estimating citation timestamps by the publication date of the citing paper. The resulting corpus covers ≈2.3M ArXiv papers, of which ≈2.0M have both access and citation sequences. To support benchmarking, we provide random train/val/labeled-test splits for papers published up to 2018-09-25 and an unlabeled-test split for later submissions; edge cases and pre-2013 access records are isolated in a train_extra split. Category distributions reflect the broader ArXiv mix (notably cs, math, cond-mat, astro-ph). Together, these design choices yield a large-scale, time-resolved testbed for lead-lag forecasting on scholarly content.
# Papers
2.3M
Time Span
2008–2025
Modalities
Accesses→Citations
GitHub Dataset
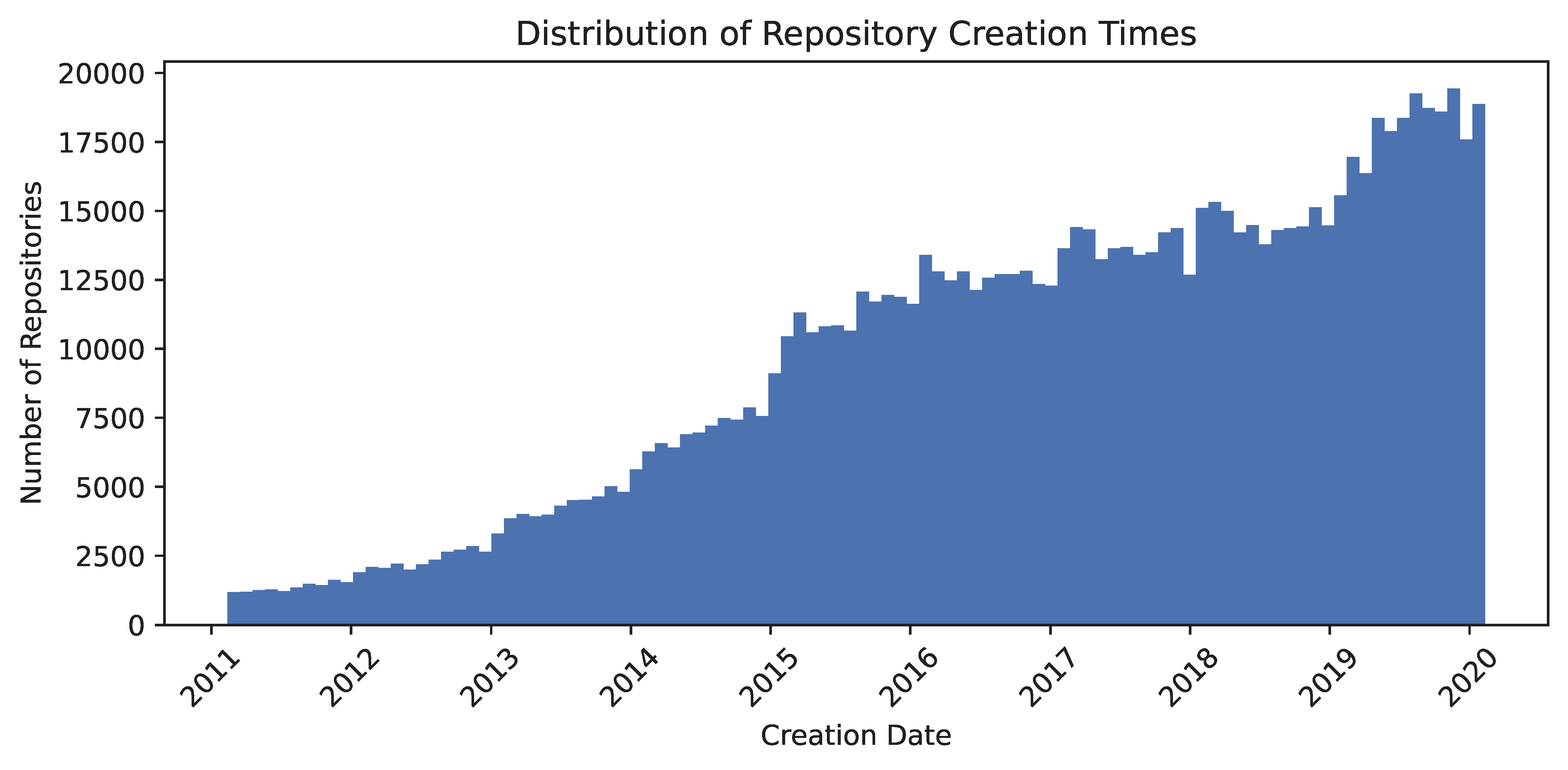
Our GitHub dataset links event data with package metadata to explore lead–lag dynamics between early developer engagement and long-term repository popularity. We construct engagement time series from GH Archive event data (coverage from 2011-02-12 onward), focusing on repositories linked to software packages from an Ecosyste.ms data dump. The left join between the Ecosyste.ms metadata and GH Archive events yields a final corpus of 3M package repositories, of which 2.9M have recorded event histories. For benchmarking, we provide random train (938K), validation (235K), and test (235K) splits. Repositories with histories shorter than five years form an unlabeled test set (1.57M), while examples with data anomalies are isolated in an extra training set (58K). The dataset’s distribution is characterized by the prevalence of packages across various software platforms. Together, these design choices yield a large-scale, time-resolved testbed for lead-lag forecasting on software development projects.
# Repos
3.0M
Time Span
2011–2025
Modalities
Pushes/Stars→Forks

BibTeX
@article{kazemian2025benchmark,
title={Benchmark Datasets for Lead-Lag Forecasting on Social Platforms},
author={Kazemian, Kimia and Liu, Zhenzhen and Yang, Yangfanyu and Luo, Katie Z and Gu, Shuhan and Du, Audrey and Yang, Xinyu and Jansons, Jack and Weinberger, Kilian Q and Thickstun, John and others},
journal={arXiv preprint arXiv:2511.03877},
year={2025}
}